



Recently, the research team led by Professor WANG Hongqiang from the Hefei Institutes of Physical Science of the Chinese Academy of Sciences, proposed a wide-ranging cross-modality machine vision AI model.
This model overcame the limitations of traditional single-domain models in handling cross-modality information and achieved new breakthroughs in cross-modality image retrieval technology.
The findings have been published in Computer Vision 2024.
Cross-modality machine vision is a major challenge in AI, as it involves finding consistency and complementarity between different types of data. Traditional methods focus on images and features but are limited by issues like information granularity and lack of data. Researchers found that detail associations are more effective in maintaining consistency across modalities than using images or features alone.
To address this, the team introduced the Wide-Ranging Information Mining Network (WRIM-Net). This model created global region interactions to extract detailed associations across various domains, such as spatial, channel, and scale domains. By doing so, it overcame the limitations of traditional models that only operated within a single domain.
Additionally, by designing a cross-modality key-instance contrastive loss, the network was effectively guided to extract modality-invariant information. Experimental validation showed the model's effectiveness on both standard and large-scale cross-modality datasets, achieving over 90% in several key performance metrics for the first time.
This model can be applied in various fields of artificial intelligence, including visual traceability and retrieval, medical image analysis, according to the team.
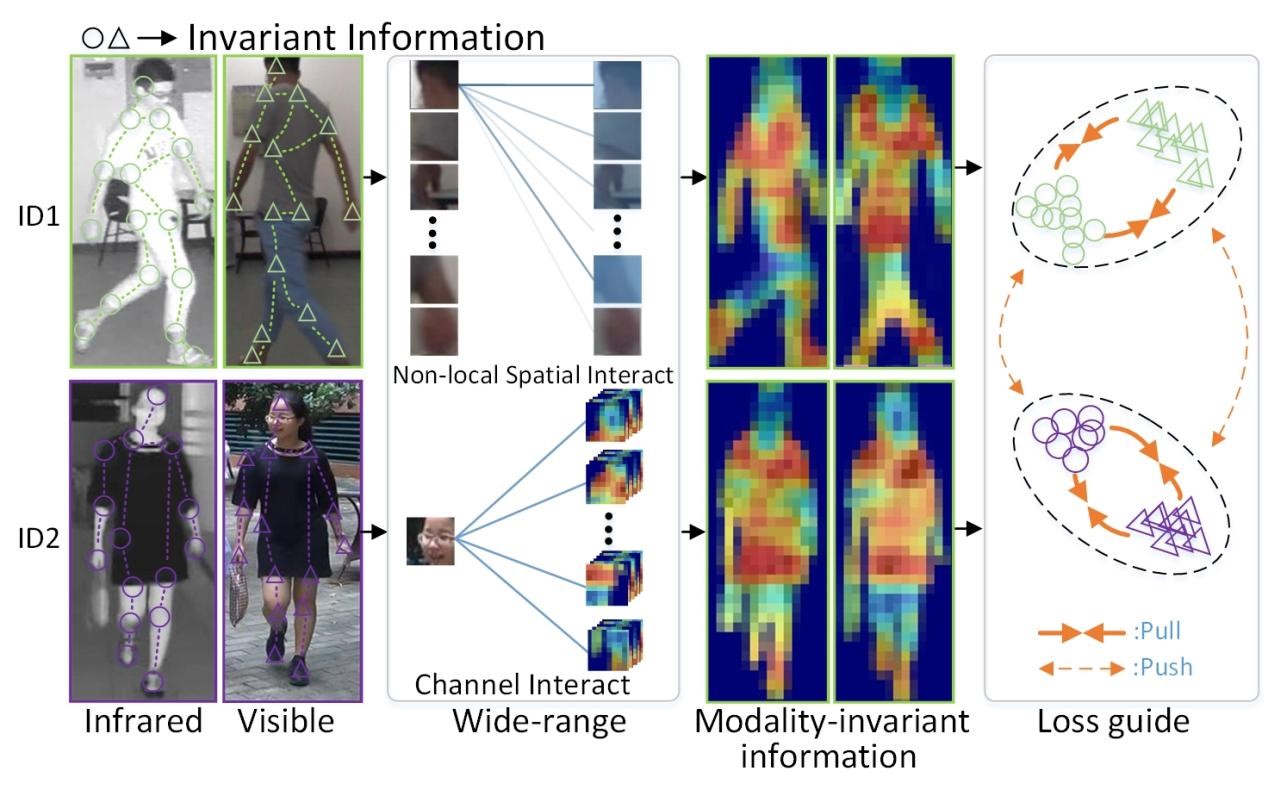
Cross-modality image retrieval workflow based on the Model (Image by WANG Hongqiang)